This explanation inspired from https://training.databricks.com/visualapi.pdf
Apache Spark RDD Operations:
Apache Spark RDD supports two types of Operations

1.RDD Transformation:
Spark Transformation is a function that produces new RDD from the existing RDDs.
Note:
It takes RDD as input and produces one or more RDD as output.
There are two types of transformations:
Each partition of the parent RDD is used by at most one partition of the child RDD.
Note:
Narrow transformations are the result of map(), filter().
ii.Wide transformations:
Multiple child RDD partitions may depend on a single parent RDD partition.

Note:
Wide transformations are the result of groupbyKey() and reducebyKey().
Let's we go through all the transformations one by one:
1)map(func)
Return a new RDD formed by passing each element of the source through a function func.
Pictorial view:
Let's consider the RDD: x is the parent RDD:
 Map transformation, to apply for each element in the parent RDD:
Map transformation, to apply for each element in the parent RDD:
1)map transformation on first element
 2)map transformation on second element
2)map transformation on second element
 3)map transformation on third element
3)map transformation on third element

4)After map(func) applied , new RDD formation
 Example: python spark:
Example: python spark:
Syntax:

Example: scala spark:

2)filter(func):
keep item if function returns true
Pictorial view:
Let's consider the RDD: x is the parent RDD:

1)filter transformation on first element

2)filter transformation on second element

3)filter transformation on third element

4)After filter(func) applied , new RDD formation

Example: python spark:
Syntax:
 Example: scala spark:
Example: scala spark:

3)flatMap(func):
Each input item can be mapped to 0 or more output items (so func should return a Seq rather than a single item).
Pictorial view:
Let's consider the RDD: x is the parent RDD:

1)flatMap transformation on first element

2)flatMap transformation on second element
 3)flatMap transformation on third element
3)flatMap transformation on third element

4)After flatMap(func) applied , new RDD formation

Example: python spark:
Syntax:

Example: scala spark:

3)mapPartitions(func):
Similar to map, but runs separately on each partition (block) of the RDD, for performance optimization.
Note:
so func must be of type Iterator<T> => Iterator<U> when running on an RDD of type T.
Pictorial view:
 Example: python spark:
Example: python spark:
Syntax:

Example: scala spark:
 Note:
Note:
Results [6,15,24] are created with mapPartitions loops through 3 partitions.
Partion 1: 1+2+3 = 6
Partition 2: 4+5+6 = 15
Partition 3: 7+8+9 = 24
To check the defualt parallelism:
4)mapPartitionsWithIndex(func):
Similar to mapPartitions, but also provides func with an integer value representing the index of the partition,
Note:
func must be of type (Int, Iterator<T>) => Iterator<U> when running on an RDD of type T.
Pictorial view:
 Example: python spark:
Example: python spark:
 Example: scala spark:
Example: scala spark:

Note:
glom() flattens elements on the same partition
5)sample(withReplacement, fraction, seed):
Sample a fraction fraction of the data, with or without replacement, using a given random number generator seed.
Pictorial view:

Example: python spark:

Example: scala spark:

6)union(otherDataset):
Return a new dataset that contains the union of two RDDs elements
Pictorial view:

Example: python spark:

Example: scala spark:

Note:Union can take duplicates as well,
7)intersection(otherDataset):
Return a new RDD that contains the intersection of elements in both RDD's
Example: python spark:

Example: scala spark:

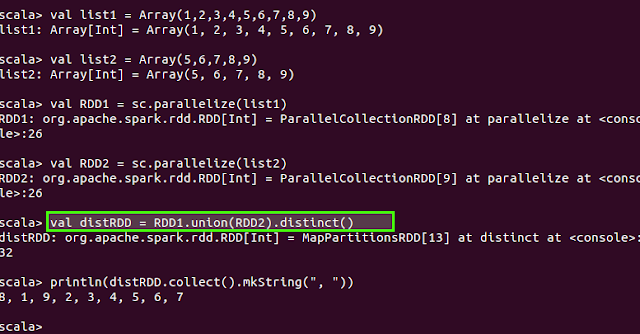
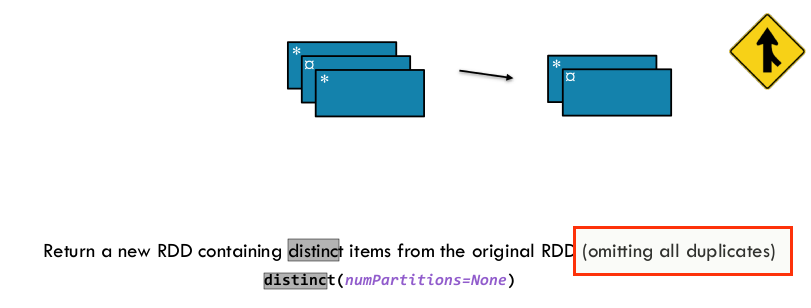
8)distinct([numTasks])):
Return a new dataset that contains the distinct elements of the source RDD.
Pictorial view:

Example: python spark:

Example: scala spark:
9)groupByKey([numTasks]):When called on a dataset of (K, V) pairs, returns a dataset of (K, Iterable<V>) pairs.
Pictorial view:

After groupByKey transformation:

Example: python spark:
 Example: scala spark:
Example: scala spark:

10)reduceByKey(func, [numTasks]):
Returns a dataset of (K, V) pairs where the values for each key are aggregated using the given reduce function func, which must be of type (V,V) => V.
Example: python spark:
 Example: scala spark:
Example: scala spark:

Apache Spark RDD Operations:
Apache Spark RDD supports two types of Operations
- Transformations
- Actions

1.RDD Transformation:
Spark Transformation is a function that produces new RDD from the existing RDDs.
Note:
It takes RDD as input and produces one or more RDD as output.
There are two types of transformations:
- Narrow transformations
- Wide transformations
Each partition of the parent RDD is used by at most one partition of the child RDD.
Note:
Narrow transformations are the result of map(), filter().
ii.Wide transformations:
Multiple child RDD partitions may depend on a single parent RDD partition.

Note:
Wide transformations are the result of groupbyKey() and reducebyKey().
Let's we go through all the transformations one by one:
| Transformations | Usage |
| i)General Transformations | |
| map(func) | Return a new RDD formed by passing each element of the source through a function func. |
1)map(func)
Return a new RDD formed by passing each element of the source through a function func.
Pictorial view:
Let's consider the RDD: x is the parent RDD:

1)map transformation on first element



4)After map(func) applied , new RDD formation

Syntax:
map(func, preserverspatitions = False)

Example: scala spark:

2)filter(func):
keep item if function returns true
| Transformations | Usage |
| i)General Transformations | |
| map(func) | Return a new RDD formed by passing each element of the source through a function func. |
| filter(func) | Return a new RDD formed by selecting those elements of the source on which func returns true. |
Pictorial view:
Let's consider the RDD: x is the parent RDD:

1)filter transformation on first element

2)filter transformation on second element

3)filter transformation on third element

4)After filter(func) applied , new RDD formation

Example: python spark:
Syntax:
filter(func)

3)flatMap(func):
Each input item can be mapped to 0 or more output items (so func should return a Seq rather than a single item).
| Transformations | Usage |
| i)General Transformations | |
| map(func) | Return a new RDD formed by passing each element of the source through a function func. |
| filter(func) | Return a new RDD formed by selecting those elements of the source on which func returns true. |
| flatMap(func) | Similar to map, but each input item can be mapped to 0 or more output items (so func should return a Seq rather than a single item). |
Pictorial view:
Let's consider the RDD: x is the parent RDD:

1)flatMap transformation on first element

2)flatMap transformation on second element


4)After flatMap(func) applied , new RDD formation

Example: python spark:
Syntax:
flatMap(func)

Example: scala spark:

3)mapPartitions(func):
Similar to map, but runs separately on each partition (block) of the RDD, for performance optimization.
Note:
so func must be of type Iterator<T> => Iterator<U> when running on an RDD of type T.
| Transformations | Usage |
| i)General Transformations | |
| map(func) | Return a new RDD formed by passing each element of the source through a function func. |
| filter(func) | Return a new RDD formed by selecting those elements of the source on which func returns true. |
| flatMap(func) | Similar to map, but each input item can be mapped to 0 or more output items (so func should return a Seq rather than a single item). |
| mapPartitions(func) | Similar to map, but runs separately on each partition (block) of the RDD |
Pictorial view:

Syntax:
mapPartitions(Iterable<T> funciton, pserversPatitioning= False)

Example: scala spark:

Results [6,15,24] are created with mapPartitions loops through 3 partitions.
Partion 1: 1+2+3 = 6
Partition 2: 4+5+6 = 15
Partition 3: 7+8+9 = 24
To check the defualt parallelism:
>>> print sc.defaultParallelism
4
4)mapPartitionsWithIndex(func):
Similar to mapPartitions, but also provides func with an integer value representing the index of the partition,
Note:
func must be of type (Int, Iterator<T>) => Iterator<U> when running on an RDD of type T.
| Transformations | Usage |
| i)General Transformations | |
| map(func) | Return a new RDD formed by passing each element of the source through a function func. |
| filter(func) | Return a new RDD formed by selecting those elements of the source on which func returns true. |
| flatMap(func) | Similar to map, but each input item can be mapped to 0 or more output items (so func should return a Seq rather than a single item). |
| mapPartitions(func) | Similar to map, but runs separately on each partition (block) of the RDD |
| mapPartitionsWithIndex(func) | Similar to mapPartitions, but also provides func with an integer value representing the index of the partition, |
Pictorial view:



Note:
glom() flattens elements on the same partition
5)sample(withReplacement, fraction, seed):
Sample a fraction fraction of the data, with or without replacement, using a given random number generator seed.
| Transformations | Usage |
| i)General Transformations | |
| map(func) | Return a new RDD formed by passing each element of the source through a function func. |
| filter(func) | Return a new RDD formed by selecting those elements of the source on which func returns true. |
| flatMap(func) | Similar to map, but each input item can be mapped to 0 or more output items (so func should return a Seq rather than a single item). |
| mapPartitions(func) | Similar to map, but runs separately on each partition (block) of the RDD |
| mapPartitionsWithIndex(func) | Similar to mapPartitions, but also provides func with an integer value representing the index of the partition, |
| ii)Math/Statistical | |
| sample(withReplacement, fraction, seed) | Sample a fraction of the data, with or without replacement, using a given random number generator seed. |
Pictorial view:

Example: python spark:

Example: scala spark:

6)union(otherDataset):
Return a new dataset that contains the union of two RDDs elements
| Transformations | Usage |
| i)General Transformations | |
| map(func) | Return a new RDD formed by passing each element of the source through a function func. |
| filter(func) | Return a new RDD formed by selecting those elements of the source on which func returns true. |
| flatMap(func) | Similar to map, but each input item can be mapped to 0 or more output items (so func should return a Seq rather than a single item). |
| mapPartitions(func) | Similar to map, but runs separately on each partition (block) of the RDD |
| mapPartitionsWithIndex(func) | Similar to mapPartitions, but also provides func with an integer value representing the index of the partition, |
| ii)Math/Statistical | |
| sample(withReplacement, fraction, seed) | Sample a fraction of the data, with or without replacement, using a given random number generator seed. |
| ii)Set Theory/Relational | |
| union(otherDataset) | Return a new dataset that contains the union of two RDDs elements |
Pictorial view:

Example: python spark:

Example: scala spark:

Note:Union can take duplicates as well,
7)intersection(otherDataset):
Return a new RDD that contains the intersection of elements in both RDD's
| Transformations | Usage |
| i)General Transformations | |
| map(func) | Return a new RDD formed by passing each element of the source through a function func. |
| filter(func) | Return a new RDD formed by selecting those elements of the source on which func returns true. |
| flatMap(func) | Similar to map, but each input item can be mapped to 0 or more output items (so func should return a Seq rather than a single item). |
| mapPartitions(func) | Similar to map, but runs separately on each partition (block) of the RDD |
| mapPartitionsWithIndex(func) | Similar to mapPartitions, but also provides func with an integer value representing the index of the partition, |
| ii)Math/Statistical | |
| sample(withReplacement, fraction, seed) | Sample a fraction of the data, with or without replacement, using a given random number generator seed. |
| ii)Set Theory/Relational | |
| union(otherDataset) | Return a new dataset that contains the union of two RDDs elements |
| intersection(otherDataset) | Return a new RDD that contains the intersection of elements in both RDD's |
Example: python spark:

Example: scala spark:

8)distinct([numTasks])):
Return a new dataset that contains the distinct elements of the source RDD.
| Transformations | Usage |
| i)General Transformations | |
| map(func) | Return a new RDD formed by passing each element of the source through a function func. |
| filter(func) | Return a new RDD formed by selecting those elements of the source on which func returns true. |
| flatMap(func) | Similar to map, but each input item can be mapped to 0 or more output items (so func should return a Seq rather than a single item). |
| mapPartitions(func) | Similar to map, but runs separately on each partition (block) of the RDD |
| mapPartitionsWithIndex(func) | Similar to mapPartitions, but also provides func with an integer value representing the index of the partition, |
| ii)Math/Statistical | |
| sample(withReplacement, fraction, seed) | Sample a fraction of the data, with or without replacement, using a given random number generator seed. |
| ii)Set Theory/Relational | |
| union(otherDataset) | Return a new dataset that contains the union of two RDDs elements |
| intersection(otherDataset) | Return a new RDD that contains the intersection of elements in both RDD's |
| distinct([numTasks])) | Return a new dataset that contains the distinct elements of the source RDD |
Pictorial view:
Example: python spark:

Example: scala spark:

9)groupByKey([numTasks]):When called on a dataset of (K, V) pairs, returns a dataset of (K, Iterable<V>) pairs.
| Transformations | Usage |
| i)General Transformations | |
| map(func) | Return a new RDD formed by passing each element of the source through a function func. |
| filter(func) | Return a new RDD formed by selecting those elements of the source on which func returns true. |
| flatMap(func) | Similar to map, but each input item can be mapped to 0 or more output items (so func should return a Seq rather than a single item). |
| mapPartitions(func) | Similar to map, but runs separately on each partition (block) of the RDD |
| mapPartitionsWithIndex(func) | Similar to mapPartitions, but also provides func with an integer value representing the index of the partition, |
| ii)Math/Statistical | |
| sample(withReplacement, fraction, seed) | Sample a fraction of the data, with or without replacement, using a given random number generator seed. |
| ii)Set Theory/Relational | |
| union(otherDataset) | Return a new dataset that contains the union of two RDDs elements |
| intersection(otherDataset) | Return a new RDD that contains the intersection of elements in both RDD's |
| distinct([numTasks])) | Return a new dataset that contains the distinct elements of the source RDD |
| groupByKey([numTasks]) | When called on a dataset of (K, V) pairs, returns a dataset of (K, Iterable<V>) pairs. |
Pictorial view:

After groupByKey transformation:

Example: python spark:


10)reduceByKey(func, [numTasks]):
Returns a dataset of (K, V) pairs where the values for each key are aggregated using the given reduce function func, which must be of type (V,V) => V.
| Transformations | Usage |
| i)General Transformations | |
| map(func) | Return a new RDD formed by passing each element of the source through a function func. |
| filter(func) | Return a new RDD formed by selecting those elements of the source on which func returns true. |
| flatMap(func) | Similar to map, but each input item can be mapped to 0 or more output items (so func should return a Seq rather than a single item). |
| mapPartitions(func) | Similar to map, but runs separately on each partition (block) of the RDD |
| mapPartitionsWithIndex(func) | Similar to mapPartitions, but also provides func with an integer value representing the index of the partition, |
| reduceByKey(func, [numTasks]) | Operates on key, value pairs again, but the func must be of type (V,V) => V. |
| ii)Math/Statistical | |
| sample(withReplacement, fraction, seed) | Sample a fraction of the data, with or without replacement, using a given random number generator seed. |
| iii)Set Theory/Relational | |
| union(otherDataset) | Return a new dataset that contains the union of two RDDs elements |
| intersection(otherDataset) | Return a new RDD that contains the intersection of elements in both RDD's |
| distinct([numTasks])) | Return a new dataset that contains the distinct elements of the source RDD |
| groupByKey([numTasks]) | When called on a dataset of (K, V) pairs, returns a dataset of (K, Iterable<V>) pairs. |
Example: python spark:






No comments:
Post a Comment